ITP GRADUATE THESIS
January - April 2020

TLDR:
This AI video series, titled "Without a Reflection," delves into the transformative impact of technology on communication, exploring the layers of abstraction introduced in the digital interaction process. By employing AI filters, both verbal (GPT-2) and visual (first-order motion model with AI-generated faces), the original intent of the messages undergoes a profound metamorphosis. The project prompts viewers to contemplate the evolving nature of human expression through technology and raises questions about the authenticity and editing of our digital selves in the communication landscape.
FULL VERSION:
The introduction of the internet and subsequent technological advancement has allowed for new ways to reflect ourselves to the world around us. These reflections, in turn, have created new forms of communication and impacted the way we interact with one another. However, an unforeseen byproduct of this technological advancement is the introduction of various layers of abstraction. As our attempts to communicate pass through these layers, the original intent begins to take on a new meaning. This project is a series of AI videos that explores how technology transforms communication into something new, a reflection from the original intent. How do we use technology to mediate our social interactions and how do these interactions form digital archetypes of ourselves?
Without a Reflection addresses these questions by adding layers of abstraction to each step of the digital communication process, until the original intent takes on an entirely new meaning. These layers act as filters for both the verbal and visual and allow us to examine each step of the process as it transforms. But like each digital message there is still a trace of its origin. So the original voice is left untouched, as a digital trace tying the viewer to the original intent.
The project leaves an openness for the viewer to decide for themselves how they feel about each output. Is this new communication part of our evolution as a species or is it taking for granted the core of what it means to be human? Should what we put forward always be edited versions of ourselves or does this allow new opportunities for self expression?
PROCESS
To examine the process, I first started with the person. I reached out to a group of people and had each person video tape themselves reading one to two lines that I gave them. By giving them a set line to say, I removed their ability to communicate their own message.
These lines were actually generated using OpenAI's natural language model GPT2. GPT-2 generates textual outputs in the style of the source text it is trained on. I trained two separate models off of two different source texts.

The first source text was taken from the Missed Connections forum, which is “a type of personal advertisement which arose after two people met but were too shy or otherwise unable to exchange contact details”. Missed connections stood at the beginning of when we started communicating online. It allowed a second chance at missed opportunities with the hope of physically meeting again.
The second source text was a collection of personal accounts of the negative and positive effects social distancing was having on people as well as the creative, fun and weird ways people were spending their time. These were found on reddit, twitter and through personal submissions of friends and others in the ITP community through google forms. Unlike Missed connections, social distancing was about starting together and moving outward into isolation, forced to communicate behind our devices. Social distancing is a total removal of our physical selves in our communication with each other.
Both source texts were chosen because they represent moments of disconnection. In total, twenty outputs were chosen, half from missed connections and the other half from social distancing. The use of GPT-2 acts as the verbal filter, diluting, scrambling our words and therefore it’s meaning. What we hear is an abstracted version of the original message.
Next, I added a visual abstraction by overlaying each person’s face with an AI generated face. These were digital reflections of our physical selves that we use to communicate. I allowed each person to choose from a collection of faces.

These faces were taken from the generated.faces dataset, which was made publicly available. These faces were generated photos created from scratch by AI systems, meaning that these were not real faces and served to act as yet another layer of abstraction, but this time a visual one. In order to overlay the faces on the videos, I ran them through the first order motion model, which is an open sourced repository for image animation.
The first order motion model takes an image that it then animates by using the facial expressions of the "driving video". The driving video is what animates the image, but does not show up in the final sequence. You can see the driving video in the GIF above to the left with the final sequence to the right. This process is similar to deepfakes. The first order motion is able to detect facial landmarks using a facial alignment network that is capable of detecting points in both 2D and 3D coordinates.
Overall, the process of abstraction looks like what you see below. The original video is put through a visual filter (first order motion model using AI faces) and a verbal language filter (GPT-2 trained off of two source texts) in order to produce the final output.
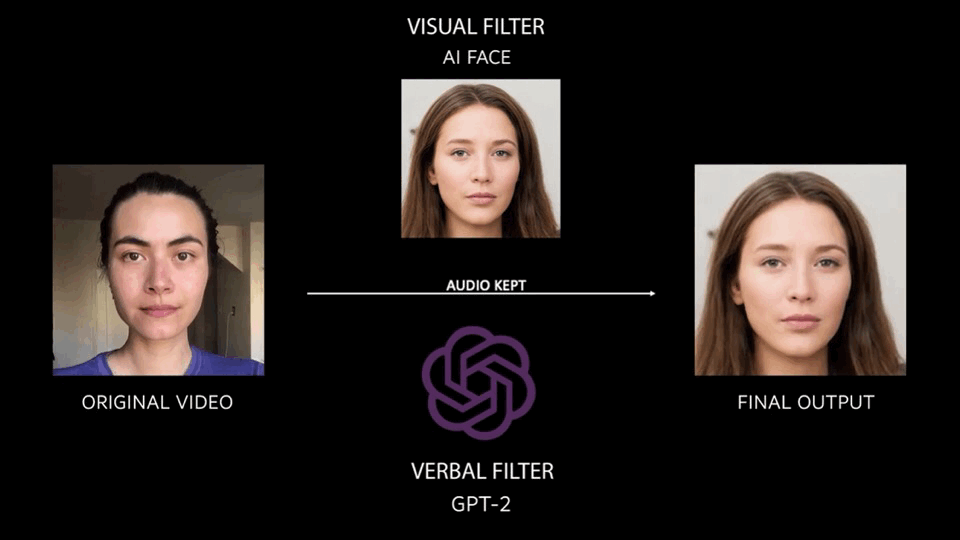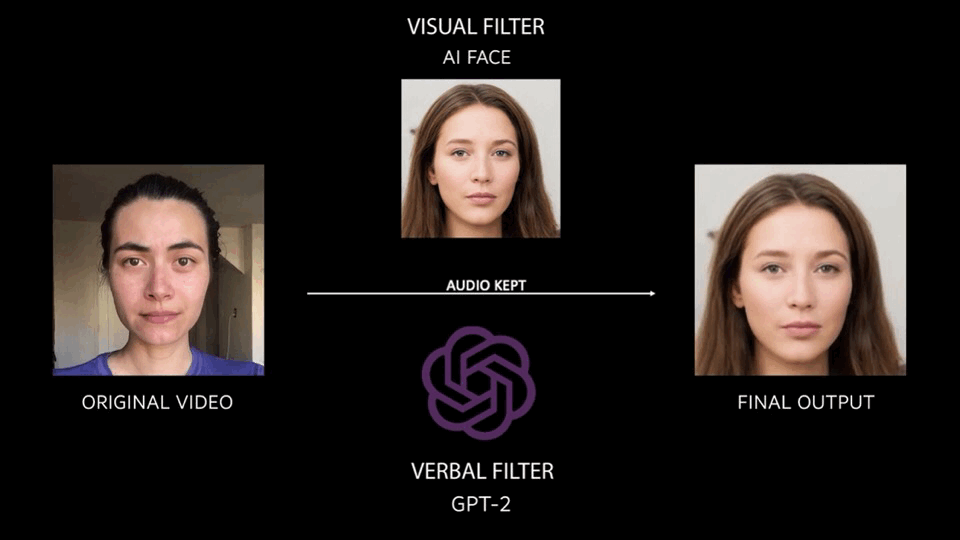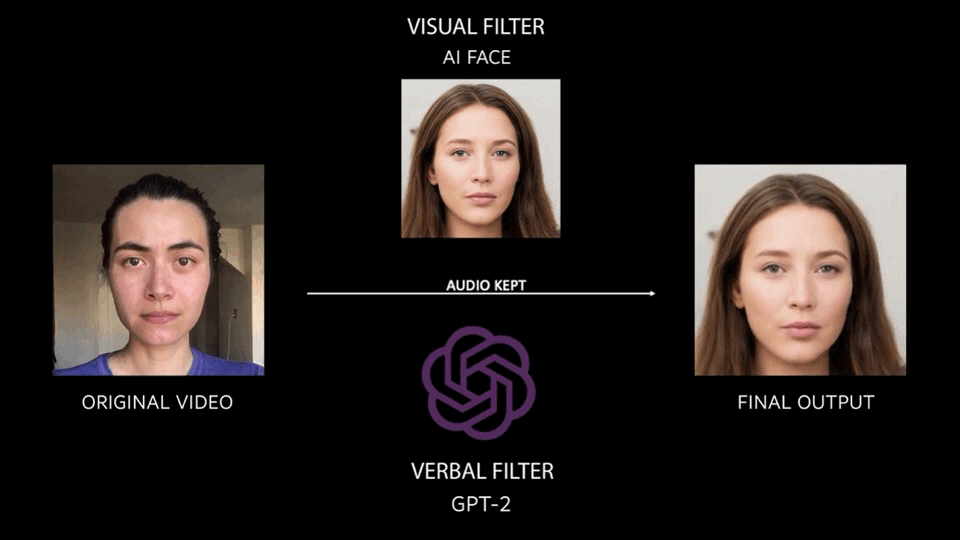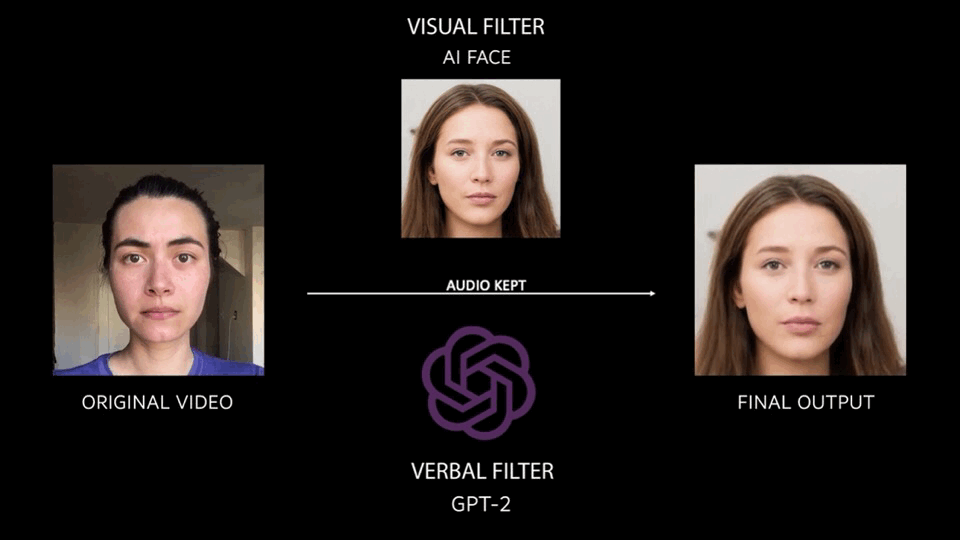
The final result is a collection of 30 outputs, read by 16 different people, and put together in a video format. For now, they follow a linear progression, but I hope in the future I will be able to lay each output in a more dynamic and exploratory way.